Lab 2: Linear Transformations and Significance Tests
PSYC 7804 - Regression with Lab
Linear Transformations
Without needing to give too formal of a definition, a linear transformation is a transformation of any variable such that the transformed variable is perfectly correlated with the original.
for example,
\[\mathrm{Wind_{New}} = \mathrm{Wind} \times 3 + 4\]
Is a linear transformation. The quickest way to get a good intuition is plotting the transformed and untransformed variables:
dat$Wind_new <- dat$Wind*3 + 4
ggplot(dat,
aes(x = Wind, y = Wind_new)) +
geom_point()
Mean-Centering and Standardization
The two linear transformations that you will come across the most are mean-centering and Standardization:
Mean-centering simply involves subtracting the mean from the original variable: \[x_{\mathrm{cent}} = x - \bar{x}\]
The only difference is that \(x_{\mathrm{cent}}\) will have a mean of 0.
Plot Code
ggplot(dat, aes(x = Wind)) +
geom_density(aes(color = "Original")) +
geom_density(aes(x = Wind - mean(dat$Wind), color = "Centered")) +
xlim(c(-10, 20)) +
scale_y_continuous(expand = c(0,0)) +
scale_color_manual(
values = c("Original" = "blue",
"Centered" = "red"),
name = "",
labels = c(
"Original" = expression(x),
"Centered" = expression(x - bar(x)))) +
theme(
axis.title.y = element_blank(),
axis.text.y = element_blank(),
axis.ticks.y = element_blank(),
axis.line.y = element_blank())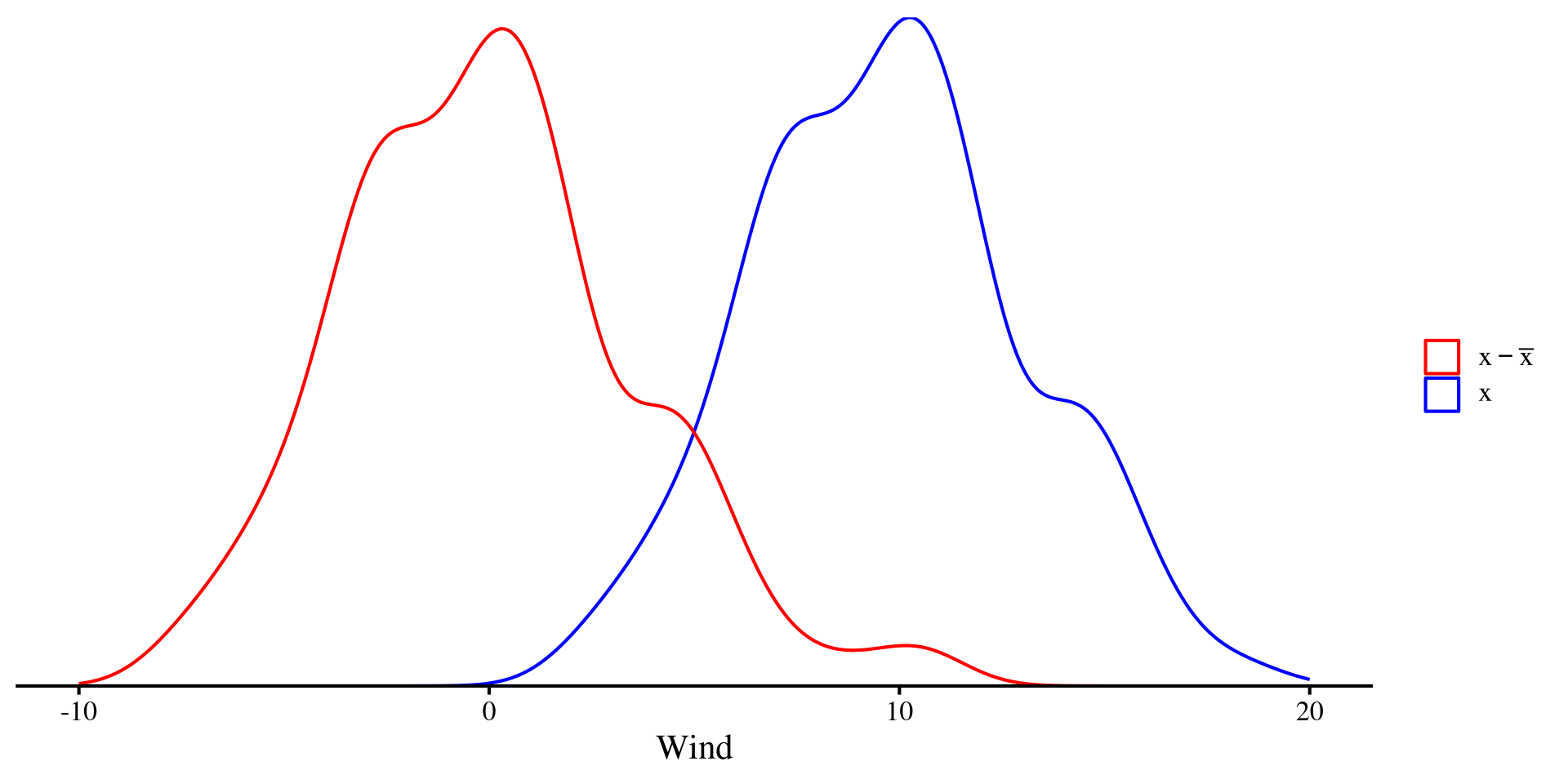
standardization involves mean-centering first and then dividing by the SD: \[x_{\mathrm{std}} = \frac{x_i - \bar{x}}{SD_x}\]
Dividing by the SD “squishes” the distribution, but the shape does not change! The only difference is that \(x_{\mathrm{std}}\) will have a mean of 0 and a standard deviation of 1.
Plot Code
ggplot(dat, aes(x = Wind)) +
geom_density(aes(color = "Original")) +
geom_density(aes(x = Wind - mean(dat$Wind), color = "Centered")) +
geom_density(aes(x = (Wind - mean(dat$Wind)) / sd(dat$Wind),
color = "Standardized")) +
xlim(c(-10, 20)) +
scale_y_continuous(expand = c(0,0)) +
scale_color_manual(
values = c("Original" = "blue",
"Centered" = "red",
"Standardized" = "purple"),
name = "",
labels = c(
"Raw" = expression(x),
"Centered" = expression(x - bar(x)),
"Standardized" = expression((x - bar(x)) / SD[x])
)
) +
theme(
axis.title.y = element_blank(),
axis.text.y = element_blank(),
axis.ticks.y = element_blank(),
axis.line.y = element_blank())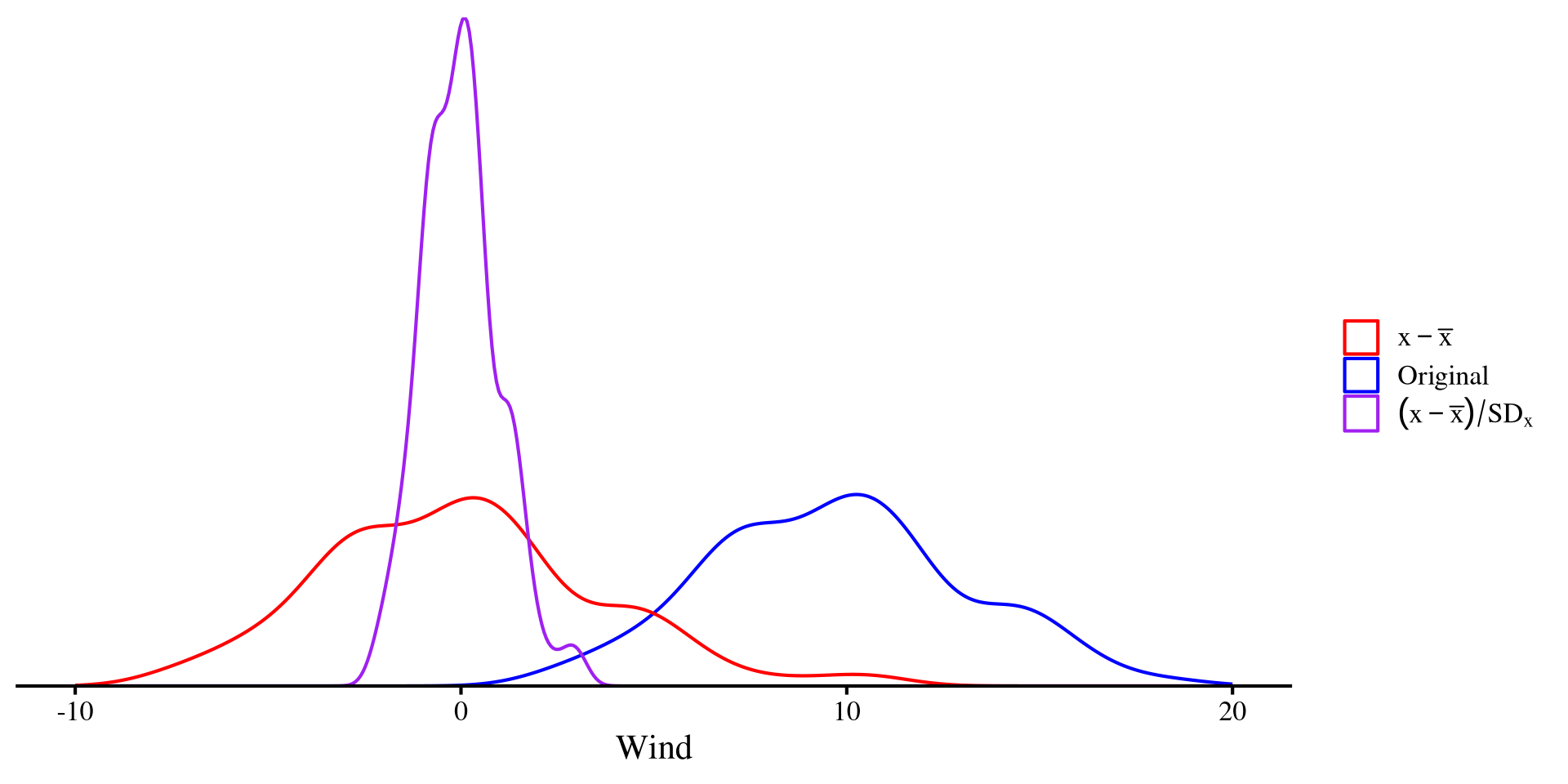
Looking at It graphically
We can see that although the equations are “different” (they are not actually), the plots are the exact same.
The only thing that changes when we plot the regression separately are the values on the axes.
Plot Code
ggplot(dat, aes(x = Wind, Temp)) +
geom_point(shape = 4) +
geom_smooth(method = "lm", se = FALSE, col = "blue")
Plot Code
ggplot(dat, aes(x = Wind_cnt, Temp_cnt)) +
geom_point(shape = 2) +
geom_smooth(method = "lm", se = FALSE)
Plot Code
ggplot(dat, aes(x = Wind_std, Temp_std)) +
geom_point(shape = 3) +
geom_smooth(method = "lm", se = FALSE, col = "red")
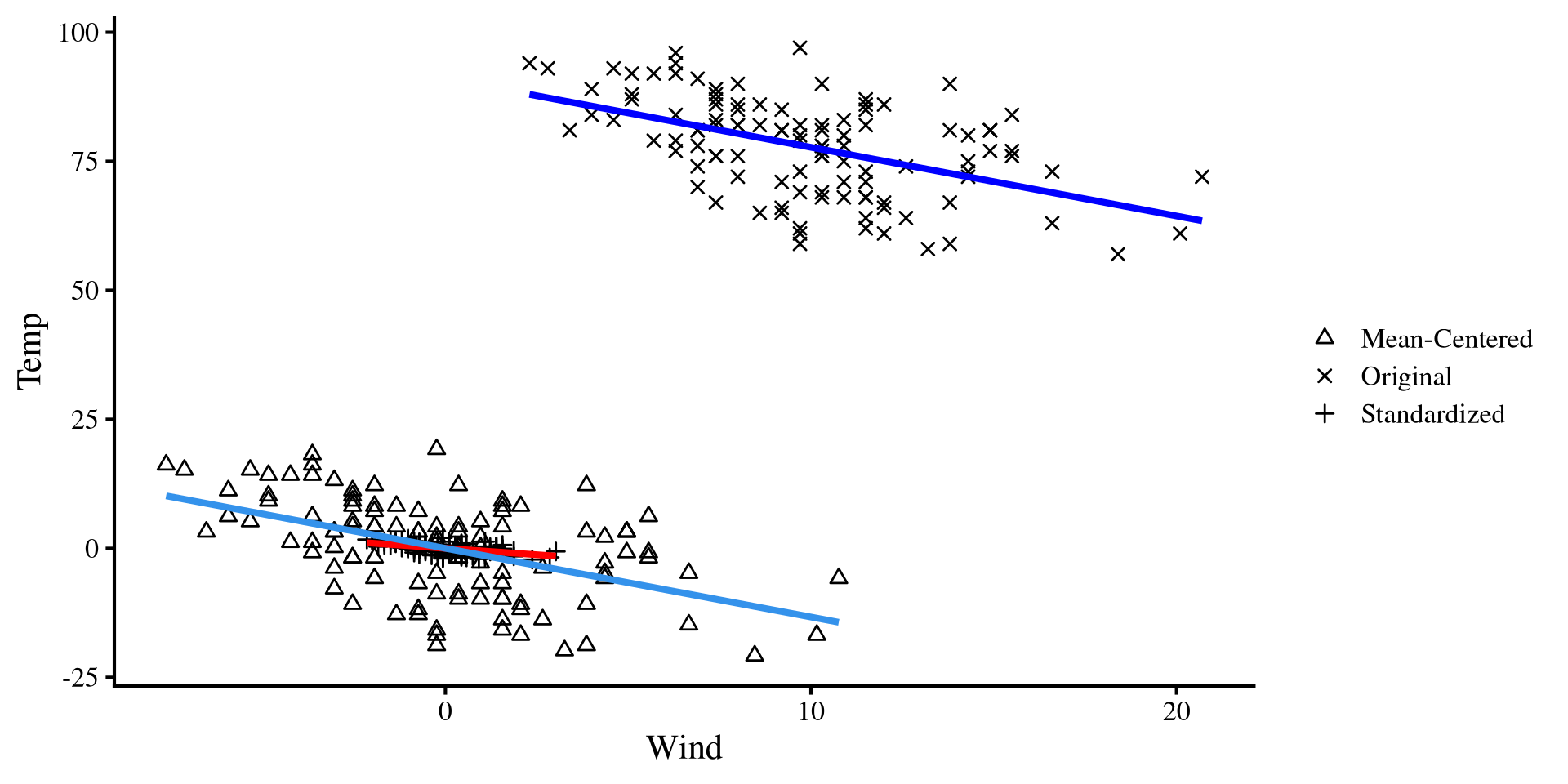
On the same plot?
We can plot the 3 regressions on the same plot to get a general sense of what is happening. All linear transformations do is move around the dots on the same cartesian plane 😀
Also notice that both the mean-centered and unstandardized regression lines are now centered at 0. That is why both of their interecept are exactly 0.
Plot Code
# Combine your data into a long format or add a "type" variable
dat_long <- data.frame(
x = c(dat$Wind_std, dat$Wind, dat$Wind_cnt),
y = c(dat$Temp_std, dat$Temp, dat$Temp_cnt),
type = factor(rep(c("Standardized", "Original", "Mean-Centered"),
times = c(nrow(dat), nrow(dat), nrow(dat))))
)
ggplot() +
# Points with legend
geom_point(data = dat, aes(x = Wind_std, y = Temp_std, shape = "Standardized")) +
geom_point(data = dat, aes(x = Wind, y = Temp, shape = "Original")) +
geom_point(data = dat, aes(x = Wind_cnt, y = Temp_cnt, shape = "Mean-Centered")) +
# Regression lines without legend
geom_smooth(data = dat, aes(x = Wind_std, y = Temp_std), method = "lm", se = FALSE, color = "red", show.legend = FALSE) +
geom_smooth(data = dat, aes(x = Wind, y = Temp), method = "lm", se = FALSE, color = "blue", show.legend = FALSE) +
geom_smooth(data = dat, aes(x = Wind_cnt, y = Temp_cnt), method = "lm", se = FALSE, show.legend = FALSE) +
# Labels and manual shapes
labs(
x = "Wind",
y = "Temp",
shape = ""
) +
scale_shape_manual(values = c("Standardized" = 3, "Original" = 4, "Mean-Centered" = 2))